02.C++ 基础精讲
本节分为 5 大类:
- 形参带默认值的函数
- 内联函数inline
- 详解函数重载
- const 深入应用
- 深入理解 C++ 的 new 和 delete
1. 形参带默认值的函数
在 C++ 中,声明一个函数时,可以为函数的参数指定默认值。当调用有默认参数值的函数时,可以不写出参数,这时就相当于以默认值作为参数调用该函数。
注意事项:
- 在有函数声明(原型)时,默认参数可以放在函数声明或定义中,但是只能放在二者之一。
1 | |
- 没有函数(原型)时,默认参数在函数定义时指定。
1 | |
- 在具有多个参数的函数中指定默认值时,默认参数都必须出现在不默认参数的右边,一旦某个参数开始指定默认值,它右边的所有参数都必须指定默认值.
就是说,函数声明时,必须按照从右向左的顺序,依次给与默认值。
原因:
函数形参的压栈过程是从右向左。详细请看:[[01.理解 C++ 内核]] 的 从指令角度掌握函数调用堆栈详细过程。
1 | |
普通函数和形参带默认值函数对比:
1 | |
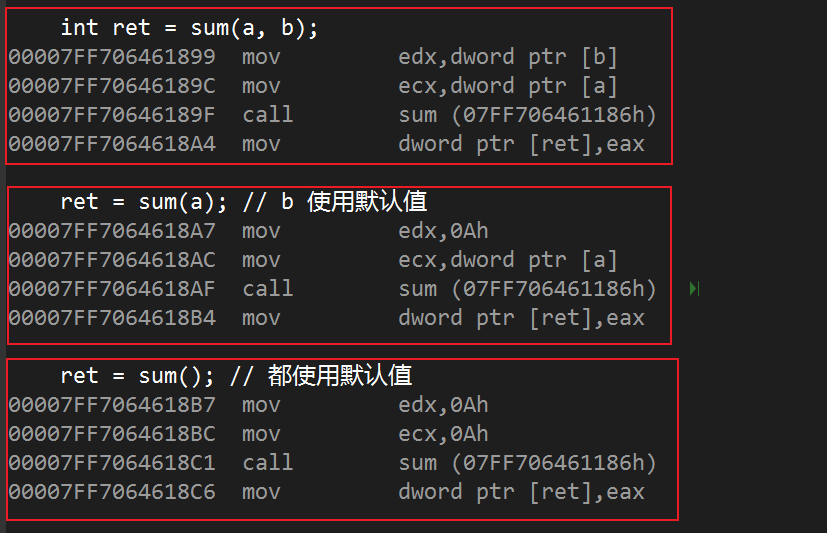
对比1,2 发现:
2 中 b 使用默认值,因此将 b 的值拷贝到寄存器后压栈,而是直接将常量0ah(10) 压栈,减少了此寄存器拷贝;
同理有3,使用默认值是:调用函数减少了 mov 指令。
2. 内联函数 inline
特征:
- 相当于把内联函数里面的内容写在调用内联函数处;
- 相当于不用执行进入函数的步骤,直接执行函数体;
- 相当于宏,却比宏多了类型检查,真正具有函数特性;
- 编译器一般不内联包含循环、递归、switch 等复杂操作的内联函数;
- 在类声明中定义的函数,除了虚函数的其他函数都会自动隐式地当成内联函数。
使用:
1 | |
编译器对 inline 函数的处理步骤:
- 将 inline 函数体复制到 inline 函数调用点处;
- 为所用 inline 函数中的局部变量分配内存空间;
- 将 inline 函数的的输入参数和返回值映射到调用方法的局部变量空间中;
- 如果 inline 函数有多个返回点,将其转变为 inline 函数代码块末尾的分支(使用 GOTO)。
内联函数与普通函数的区别?
- 内联函数;在编译过程中,就没有函数调用开销。在函数的调用点直接将函数的代码进行展开处理
[[01.理解 C++ 内核]] 中的 从指令角度掌握函数调用堆栈详细过程 知道,在调用函数的过程中:
(1)将函数实数从右向左压栈
(2)call指令:
将下一行要执行的代码地址入栈
跳转到函数入口:首先push ebp,将栈底指针入栈,然后给函数开辟栈帧函数执行结束后,栈帧回退。
在函数调用中,有大量的函数调用开销。如果封装的函数内容简单,函数调用的开销大于函数指令的执行时间,那么就可以使用内联函数(需要大量调用,且指令简单)。在调用点展开内联函数指令
内联函数不在生成相应的函数符号
inline 只是建议编译器把这个函数处理成内联函数,具体会由编译器处理觉得是否展开成内联函数。
注意:
(1)如果用vs调试Debug,不会将函数展开成内联.release版本可以。
优缺点:
优点
- 内联函数同宏函数一样将在被调用处进行代码展开,省去了参数压栈、栈帧开辟与回收,结果返回等,从而提高程序运行速度。
- 内联函数相比宏函数来说,在代码展开时,会做安全检查或自动类型转换(同普通函数),而宏定义则不会。
- 在类中声明同时定义的成员函数,自动转化为内联函数,因此内联函数可以访问类的成员变量,宏定义则不能。
- 内联函数在运行时可调试,而宏定义不可以。
缺点
- 代码膨胀。内联是以代码膨胀(复制)为代价,消除函数调用带来的开销。如果执行函数体内代码的时间,相比于函数调用的开销较大,那么效率的收获会很少。另一方面,每一处内联函数的调用都要复制代码,将使程序的总代码量增大,消耗更多的内存空间。
- inline 函数无法随着函数库升级而升级。inline函数的改变需要重新编译,不像 non-inline 可以直接链接。
- 是否内联,程序员不可控。内联函数只是对编译器的建议,是否对函数内联,决定权在于编译器。
3. 详解函数重载
函数重载:一组函数,其中函数名相同,参数列表的个数或者类型不同,那么这一组函数就称作函数重载。函数重载发生在编译时期。
(1)函数重载与函数返回值无关,因为在产生符号时没有返回值
(2) 函数重载需要在同一个作用域
(3)const 或者 volatile 的时候,是如何影响形参的
C++ 支持函数重载,而 C 则不支持:
编译器产生的函数符号规则不同:
- C++ 代码:函数符号包含了函数名和参数列表
- C 代码:函数符号只包含了函数名。
注意事项:
** 函数重载需要在同一个作用域下。**
1 | |

由于在局部作用域声明了新的 compare,导致无法重载外部作用域的 compare。
const int 和 int 的重载:
1 | |

原因:
1 | |
const int 和 int 在编译器看来都是 int 类型 ,无法完成重载。
3.1 C++ 和 C 语言如何相互调用
由于 C++ 和 C 语言的编译器生成的函数符号不同,在 C++ 使用 c 语言需要使用exten “C”{};
1. C++ 调用 C
对于c++,由于c++的编译器对c语言兼容,因此在c++中调用c语言编写的函数,只需要在函数声明前面加上关键字extern "C",表示采用类c语言的方式解析函数符号。例子如下:
1 | |
在例子中,main.cpp 为c++ 代码,add.c 为 c 语言代码,当 c++ 编译器识别到extern "C" 关键字时,会去寻找 _add_ 函数的实现而不是寻找类似_int_add_int_int_ 这样带参数信息的函数实现。
2. C 调用 C++
c 语言调用 c++ 代码却并不容易,原因是 c 语言并不兼容 c++。就算 c 语言可以调用 c++,也会因为无法识别 c++ 新定义的符号而编译报错。因此,为了实现 c 语言调用 c++ 函数,必须实现以下两个步骤:
- 将 c++ 相关函数封装为静态库或动态库(因为调用库函数时编译器并不知道里面执行的是什么语言);
- 对外提供遵循类 c 语言规约的接口函数。例子如下所示:
1 | |
通过将 _cout_函数封装为类 c 语言规约的接口函数,使得 main.c 中可以成功调用 c++ 函数 _printNum_ 。值得注意的是,main.c 不可以直接引入 printNum.h,因为 c 语言不能识别 extern "C" 关键字。可以利用 c++ 预定义宏实现头文件的改写:
1 | |
3. 总结
- c 语言与 c++ 的相互调用可以通过
extern "C"关键字实现 - c++ 中调用 c 代码,只须在 c++ 中为 c 代码函数声明之前加上
extern "C" - c 语言调用 c++ 代码,则需要将 c++ 代码编译成静态库或动态库,然后对外提供用
extern "C"声明的类 c 封装函数
4. const 深入应用
const 作用:
- 修饰变量,说明该变量不可以被改变;
- 修饰指针,分为指向常量的指针(pointer to const)和自身是常量的指针(常量指针,const pointer);
- 修饰引用,指向常量的引用(reference to const),用于形参类型,即避免了拷贝,又避免了函数对值的修改;
- 修饰成员函数,说明该成员函数内不能修改成员变量。
const 的指针与引用:
- 指针
- 指向常量的指针(pointer to const)
- 自身是常量的指针(常量指针,const pointer)
- 引用
- 指向常量的引用(reference to const)
- 没有 const reference,因为引用只是对象的别名,引用不是对象,不能用 const 修饰
1 | |
宏定义 #define 和 const 常量:
| 宏定义 #define | const 常量 |
|---|---|
| 宏定义,相当于字符替换 | 常量声明 |
| 预处理器处理 | 编译器处理 |
| 无类型安全检查 | 有类型安全检查 |
| 不分配内存 | 要分配内存 |
| 存储在代码段 | 存储在数据段 |
可通过 #undef 取消 |
不可取消 |
1. C++ 和 C 的 const 区别
- c语言中,const修饰的值,可以不用初始化,不叫常量,叫做常变量;

最终输出为:30、30、30
- C++中: const 定义的类型必须初始化,否则报错,c 语言中可以不初始化
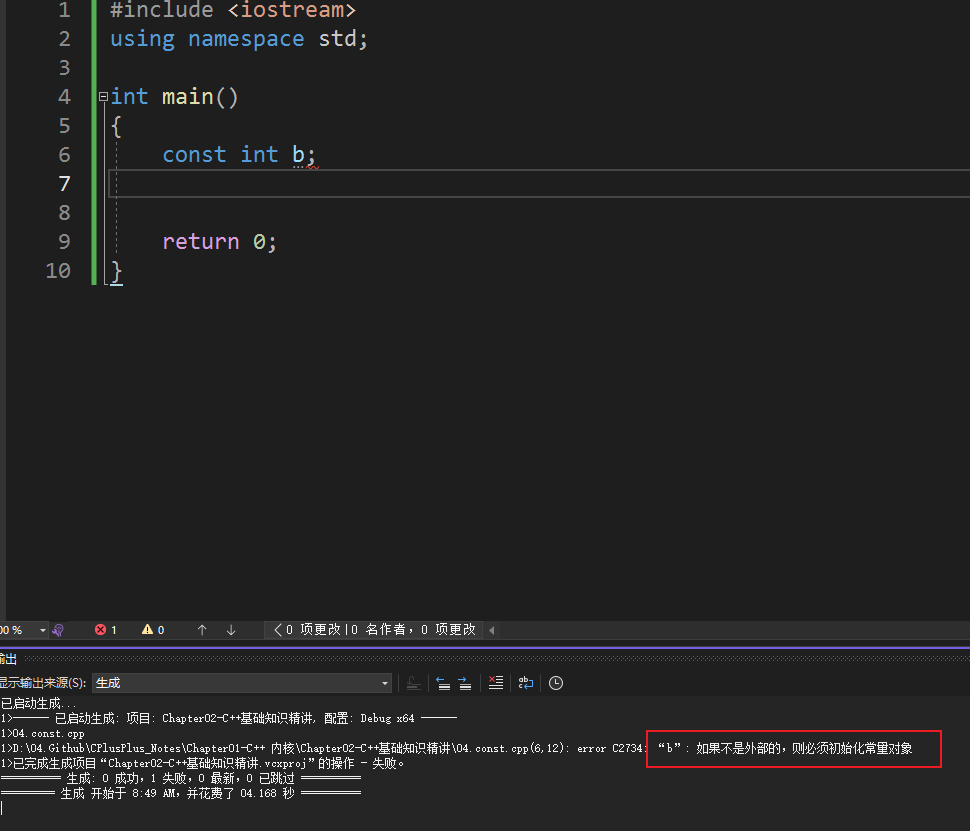
1 | |
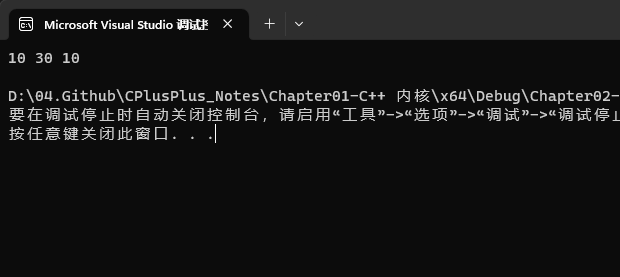
原因:const 的编译方式不同,C 语言中,const 就是当作一个变量来编译生成指令的。C++ 中,如果 const 赋值是一个立即数,所有出现 const 常量名字的地方,都被常量的初始化所替换。
1.1 Debug 调试
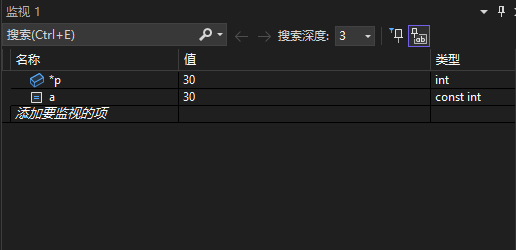
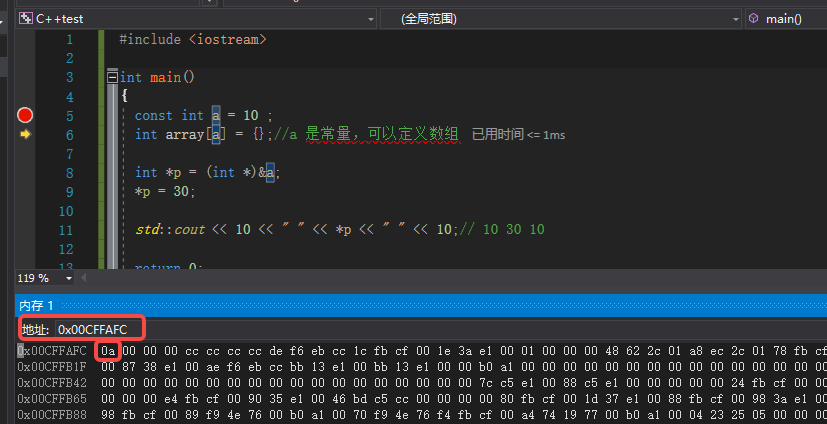
执行完第9行后 a 的内存中的值变成 1e 也即 30;但是本来出现 a 的地方在编译期已经被替换成 10,因此输出 a 依然是 10。
如果不是立即数,则是常变量
1 | |
2. const 与指针
const 修饰的量常出现的错误:
(1)常量不能再作为左值
(2)不能把常量的地址泄露给一个普通的指针或者普通的引用变量
2.1 const 和 一级指针
const 如果右边没有指针*,则const 是不参与类型的
C++的语言规范:就近原则 const 修饰的是离它最近的类型
const int* p;离 const 最近的类型是 int,所以 const 修饰的是*p,所以*p无法修改值;可以指向任意 int 的内存,但是不能通过指针简介修改内存的值。int const* p;*不是类型,离 const 最近的类型为 int,*p无法修改,同(1)int* const p;离 const 最近的类型为(int*),const 修饰的是 p,所以不能改变 p 指向的地址,但是可以修改 p 指向的地址的内容。const int* const p;不能修改 p 指向的地址和值。
1 | |
重点:
const 如果右边没有指针
*,则 const 是不参与类型的,仅表示 const 修饰的是一个常量,不能作为左值。const 类型转化公式:
const int*<=int*可以转换int*<=const int*错误
示例1:
1 | |
示例2:
1 | |
2.2 const 和 二级指针
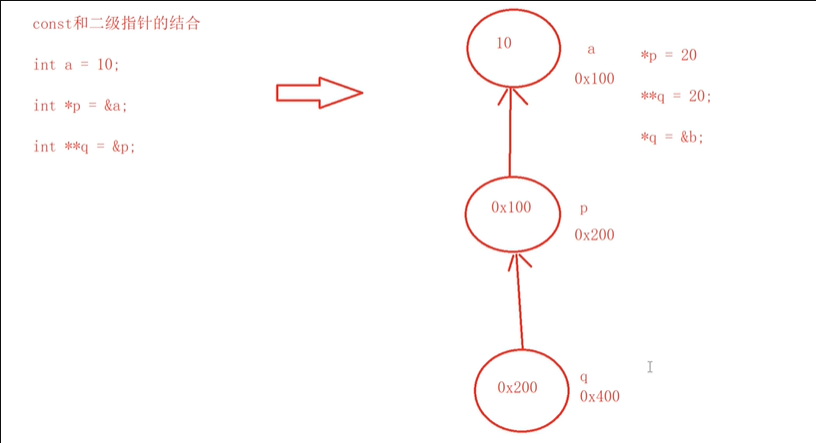
const int** q;离 const 最近的类型为 int,修饰的是**q。int* const* q;离 const 最近的类型为int*,修饰的是*q。int** const q;离 const 最近的类型为int**,修饰的是q,同时 const 右侧没有*,q 是int**类型。
转化公式:
int**<=const int**错误const int **<=int **错误
const 与二级指针结合的时候,两边必须同时有 const 或没有 const 才能转换;
int**<=int* const*是 const 和一级指针的结合,const 右边修饰的*(等同于int *<=const int *)错误的int* const*<=int**(等同于const int *<=int)可以的
要看 const 右边的 * 决定 const 修饰的是类型
1 | |
3. 引用
- 引用是必须初始化的,指针可以不初始化。
- 引用只有一级引用,没有多级引用;指针可以有一级指针,也可以用多级指针。
- 定义一个引用变量和定义一个指针变量,其汇编指令是一样的;通过引用变量修改所引用内存的值,和通过指针解引用修改指针指向的内存的值,其底层指令也是一模一样的。
引用的错误用法 int &a = 10; 由下面的反汇编可以知道,引用的汇编代码第一步是将引用对象的地址拷贝到寄存器中,10是常量;
1 | |
输出:
反汇编:指针和引用没有区别
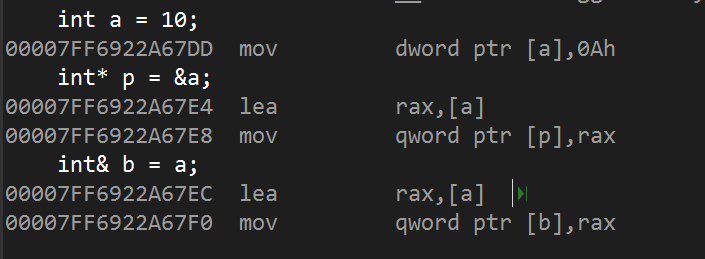
lea eax,[a]:将 a 的地址拷贝到寄存器 eax 中
mov dword ptr [p],eax:将 eax 中的值拷贝到 p 中。
反汇编中指针和引用拷贝也是没有区别。


对指针和引用赋值,都是一样的:获取地址,然后赋值。
3.1 引用别名
1 | |
关于定义一个引用类型,到底需不需要开辟内存空间,我认为是需要的,上面的汇编代码中,引用和指针的汇编是一模一样的;C++ 中只有 const 类型的数据,要求必须初始化。而引用也必须要初始化,所以引用是指针,还应该是 const 修饰的常指针。 一经声明不可改变。
站在宏观角度,引用也就是别名,所以不开辟看空间。
站在微观的角度,引用至少要保存一个指针,所以一定要开辟空间。站在底层实现的角度,站在 C++ 对于 C 实现包装的角度,引用就是指针。那么既然是指针至少要占用 4 个字节空间。
4. 左值引用
左值:有内存地址,有名字,值可以修改;
如 int a = 10; int &b =a;
int &c =10; //错误 20 是右值,20 = 40 是错误的,其值不能修改,没内存,没名字,是一个立即数;
上述代码是无法编译通过的,因为 10 无法进行取地址操作,无法对一个立即数取地址,因为立即数并没有在内存中存储,而是存储在寄存器中,可以通过下述方法解决:
1 | |
使用常引用来引用常量数字 10,因为此刻内存上产生了临时变量保存了 10,这个临时变量是可以进行取地址操作的,因此var引用的其实是这个临时变量,相当于下面的操作:
1 | |
根据上述分析,得出如下结论:
左值引用要求右边的值必须能够取地址,如果无法取地址,可以用常引用;
但使用常引用后,我们只能通过引用来读取数据,无法去修改数据,因为其被 const 修饰成常量引用了。
那么 C++11 引入了右值引用的概念,使用右值引用能够很好的解决这个问题。
5. 右值引用
C++ 对于左值和右值没有标准定义,但是有一个被广泛认同的说法:
- 可以取地址的,有名字的,非临时的就是左值;
- 不能取地址的,没有名字的,临时的就是右值;
可见立即数,函数返回的值等都是右值;而非匿名对象(包括变量),函数返回的引用,const 对象等都是左值。
从本质上理解,创建和销毁由编译器幕后控制,程序员只能确保在本行代码有效的,就是右值(包括立即数);而用户创建的,通过作用域规则可知其生存期的,就是左值(包括函数返回的局部变量的引用以及 const 对象)。
int &&c = 10;专门用来引用右值类型,指令上,可以自动产生临时量,然后直接引用临时量 c = 1;
反汇编:
- 一个右值引用变量,本身是一个左值,只能用左值引用来引用它;不能用一个右值引用变量来引用一个左值
1 | |
5. 深入理解 C++ 的 new 和 delete
New 的不同使用方式:
1 | |
1. malloc 与 new 的区别
- malloc 按字节开辟内存的;new 开辟内存时需要指定类型;
- malloc 开辟内存返回的都是
void *,new 相当于运算符重载函数,返回值自动转为指定的类型的指针。 - malloc 只负责开辟内存空间,new 不仅仅也有 malloc 功能,还可以进行数据的初始化。
- malloc 开辟内存失败返回 nullptr 指针;new 抛出的是 bad_alloc 类型的异常。
- malloc 开辟单个元素内存与数组内存是一样的,都是给字节数;new开辟时对单个元素内存后面不需要
[],而数组需要[]并给上元素个数。
2. free 和 delete 的区别:
- free 不管释放单个元素内存还是数组内存,只需要传入内存的起始地址即可。
- delete 释放单个元素内存,不需要加中括号,但释放数据内存时需要加中括号。
- delete 执行其实有两步,先调用析构,再释放;free 只有一步。
3. 解析
代码:
1 | |
反汇编:
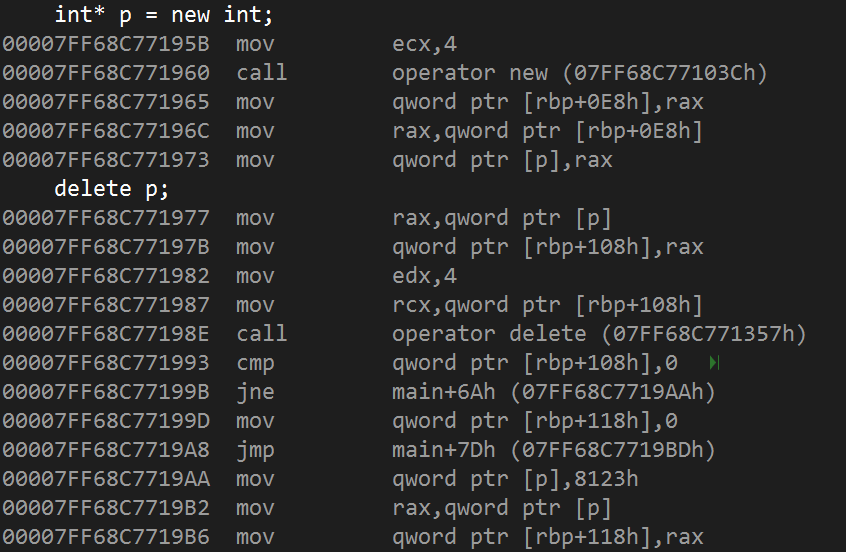
new 与 delete 其本质也是函数的调用:运算符重载 new delete
1 | |
4. 实现
1 | |
5. new 和delete 能够混用吗?
C++为什么区分单个元素和数组的内存分配和释放呢?
情况1:int类型下将其混用
1 | |
能够混用。对于整型来说,没有构造函数与析构函数,针对于 int 类型,new 与 delete 功能只剩下 malloc 与 free 功能,可以将其混用。
情况2:类类型下将其混用
1 | |
- 单个元素与
delete[]混用:
1 | |
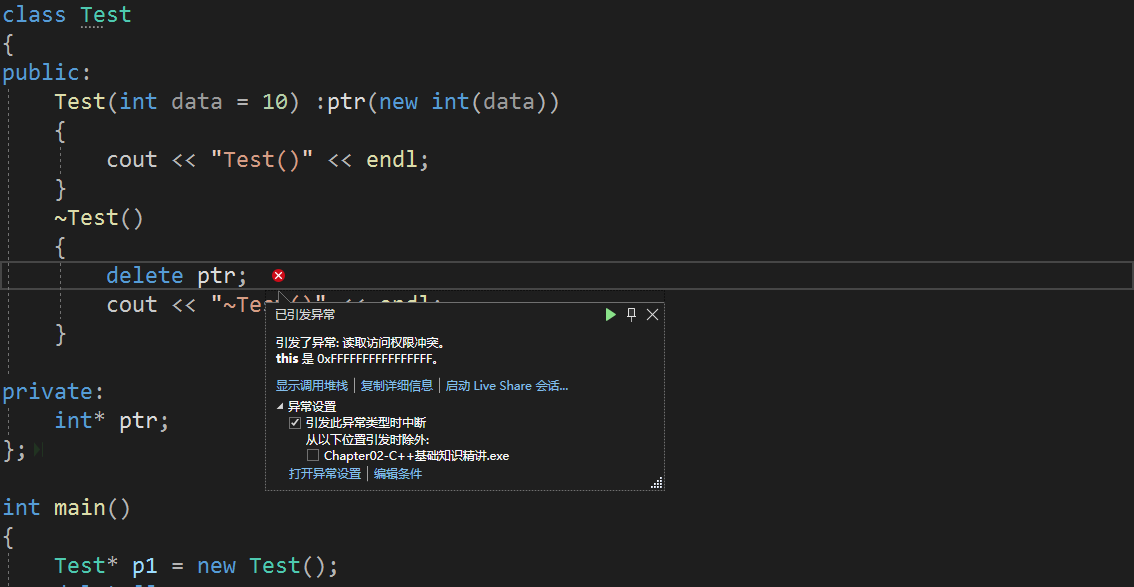
程序崩溃。
- 数组与 delete 进行混用
1 | |
程序崩溃。
分析:
正常情况下,每一个 Test 对象有一个整型成员变量,这里分配了 5 个 Test 对象。delete 时先调用析构函数,this 指针将正确的对象的地址传入析构函数中,加了 [] 表示有好几个对象,有一个数组其中每一个对象都要进行析构。但 delete 真正执行指令时,底层是 malloc 按字节开辟,并不知道是否开辟了 5 个 Test 对象的数组,因此还要再多开辟一个 4 字节来存储对象的个数,假设它的地址是 0x100;但是 new 完之后 p2 返回的地址是 0x104 地址,当我们执行 delete[] 时,会到 4 字节来取一下对象的个数,将知道了是 5 个并将这块内存平均分为 5 份,将其每一份对象起始地址传给相应的析构函数,正常析构,最后将 0x100 开始的 4 字节也释放。
而 p2 出错是给用户返回的存对象开始的起始地址,delete p2 认为 p2 只是指向了一个对象,只将 Test[0] 对象析构,直接从 0x104 free(p2),但底层实际是从 0x100 开辟的,因此崩溃。
而 p1 出错:p1 只是单个元素,从 0x104 开始开辟内存,但是 delete[] p1,里面并没有那么多元素,最后还释放了 4 个字节的存储对象个数的内存(即从 0x100 释放)因此崩溃。
